Thread
- 프로세스 내부에 여러개의 실행 단위(스레드)가 존재할수 있다
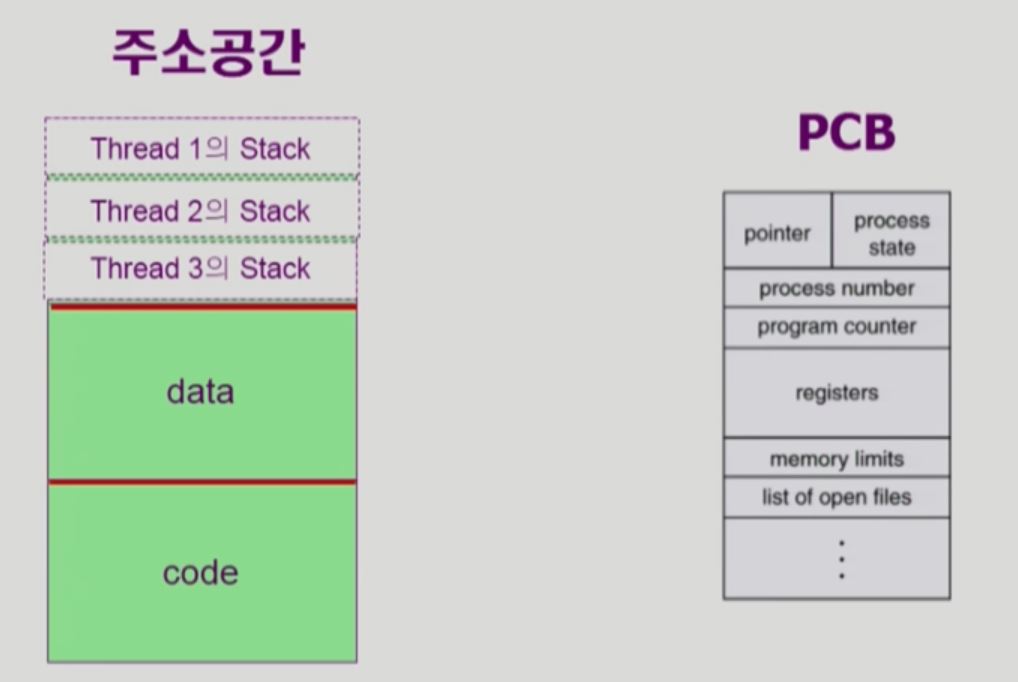
- 프로세스 하나일때의 사진, 프로세스마다 stack, data, code가 존재한다
- 해당 프로세스의 PCB에는 PC(program counter)가 있어 어느 code 부분을 실행중인지 알려준다
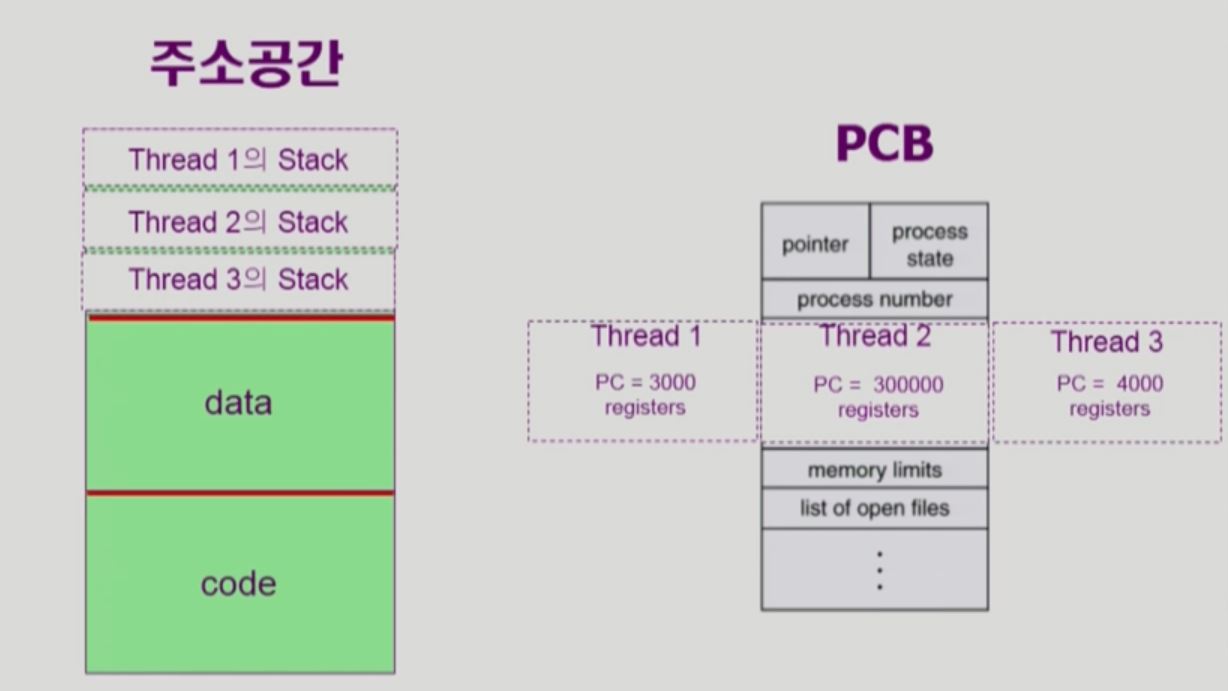
- 하나의 프로세스에 여러개의 스레드가 있을떄
- 프로세스는 똑같이 stack, data, code가 생성됨
- 각 스레드마다 어떤 code를 가르키고 있는지 PC만 다름
- 같이 공유할수 있는 자원은 최대한 공유하자
- 같이 공유하는 자원(프로세스가 사용하는 각종 자원들):
code section, data section, OS resource
- 공유 안하는것(CPU 수행과 관련된 정보, task 라고 부름):
PC - 어느 위치를 실행하는지 알려주기 위해
register set - 각각 실행하는 부분이 다르니 메모리도 다름
stack space - 함수 호출을 각각 다르게 해야하기 때문에 stack은 나눔
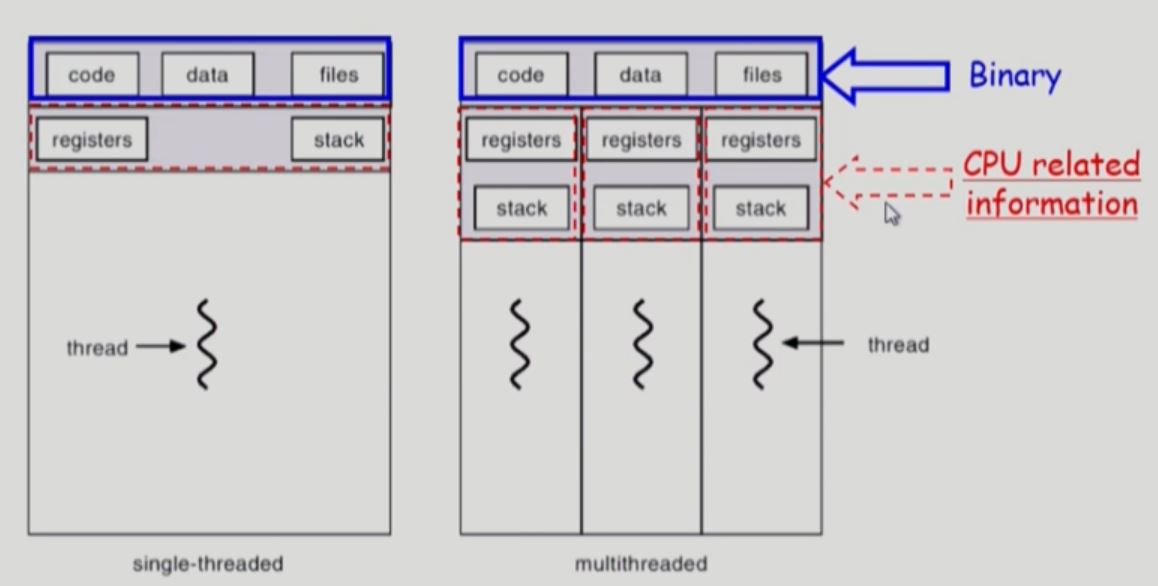
- code, data 등 공유할수 있는 자원은 공유하고
- registers, stack 등 공유할수 없는 자원만 따로 쓴다
스레드의 장점:
- 프로세스를 여러개 두는것 보다 하나의 프로세스 안에 스레드를 만드는게 더 가벼움
- 하나의 스레드가 블락 상태인 동안에도 동일한 태스크 내의 다른 스레드가 실행 되어 빠른 처리를 할수있다
ex) 웹브라우저가 웹페이지를 불러올때 html을 먼저 가져오고 img 태그는 나중에 가져오는데, 이것도 I/O 작업이기 때문에 속도가 느림, I/O 작업을 하는 동안 화면에 멈춰있으면(블락시키면) 사용자가 답답하게 느끼기 때문에 하나의 스레드가 이미지 가져오는 작업을 담당하고 하나의 스레드는 먼저 가져온 html을 화면에 뿌리는 일을 맡으면 사용자의 답답함을 해결해줄수 있음
- 이렇게 처리되는 건 I/O 결과를 보지 않고 다음 일을 수행하는 것이기 때문에 비동기식 입출력이라고 볼수있음

1. 응답성: 사용자가 느끼기에 응답 속도가 빠름
2. 자원공유: 하나의 프로세스에서 CPU 실행 단위만 여러개 만들면 자원을 효율적으로 사용 가능
3. 경제성: 프로세스 하나를 만드는 오버헤드는 크지만 스레드 하나를 만드는 오버헤드는 적음, 프로세스끼리 CPU switching의 오버헤드는 크지만 스레드끼리 오버헤드는 적음
4. CPU가 여러개일 경우 각 스레드마다 CPU를 하나씩 줘 일을 병렬적으로 처리할 수 있음
스레드를 구현하는 방법:

1. 운영체제 커널의 지원을 받음, Kernel Threads
- 스레드가 여러개라는 걸 운영체제가 알고있음
- 스레드에서 스레드로 CPU가 넘어가는 것도 커널이 넘겨줌
2. 라이브러리 형태로 구현함, User Threads
- 스러드가 여러개라는걸 운영체제가 모름
- 라이브러리 지원을 받아 스레드를 관리
- 커널이 모르기 때문에 제약이 있을 수 있음
3. real-time 스레드도 존재
'[개발일지] > 필기' 카테고리의 다른 글
| CPU Scheduling (0) | 2021.08.15 |
|---|---|
| Process Management (0) | 2021.08.12 |
| Process1 (0) | 2021.08.03 |
| System Structure & Program Execution 2 (0) | 2021.07.28 |
| System Structure & Program Execution 1 (0) | 2021.07.25 |